Tutorials & How-Tos
Introduction
Overview
Disclaimer
Please note that some of the tutorials and how-tos listed here use internal API. Please be aware that these may change in future releases and therefore may be unstable. This is due to the fact that we do not guarantee backward compatibility for internal API.On this page we have listed several tutorials and how-tos. Our goal in providing these is to ease your development efforts and help you understand some concepts that we apply.
Concepts
Error Handling
Error Handling Strategies
There are a couple of basic strategies to handle errors and exceptions within processes. The decision which strategy to use depends on:
- Technical vs. Business Errors: Does the error have some business meaning and causes an alternative process flow (like "item not on stock") or is it a technical malfunction (like "network currently down")?
- Explicit error handling or generic approach: For some situations you want to explicitly model what should happen in case of an error (typically for business errors). For a lot of situations you don't want to do that but have some generic mechanism which applies for errors, simplifying your process models (typical for technical errors, imagine you would have to model network outage on every task were it might possibly occur? You wouldn't be able to recognize your business process any more).
In the context of the process engine, errors are normally raised as Java exceptions which you have to handle. Let's have a look at how to handle them.
Transaction Rollbacks
The standard handling strategy is that exceptions are thrown to the client, meaning that the current transaction is rolled back. This means that the process state is rolled back to the last wait state. This behavior is described in detail in the Transactions in Processes section of the User Guide. Error handling is delegated to the client by the engine.
Let's show this in a concrete example: the user gets an error dialog on the frontend stating that the stock management software is currently not reachable due to network errors. To perform a retry, the user might have to click the same button again. Even if this is often not desired it is still a simple strategy applicable in a lot of situations.
Async and Failed Jobs
If you don't want the exception being shown to the user, one option is to make service calls which might cause an async error as described in Transactions in Processes. In that case the exception is stored in the process engine database and the Job in the background is marked as failed (to be more precise, the exception is stored and some retry counter is decremented).
In the example above this means that the user will not see an error but an "everything successful" dialog. The exception is stored on the job. Now either a clever retry strategy will automatically re-trigger the job later on (when the network is available again) or an operator needs to have a look at the error and trigger an additional retry. This is shown later in more detail.
This strategy is pretty powerful and applied often in real-life projects, however, it still hides the error in the BPMN diagram, so for business errors which you want to be visible in the process diagram, it would be better to use Error Events.
Catch Exception and use data based XOR-Gateway
If you call Java Code which can throw an exception, you can catch the exception within the Java Delegate, CDI Bean or whatsoever. Maybe it is already sufficient to log some information and go on, meaning that you ignore the error. More often you write the result into a process variable and model an XOR-Gateway later in the process flow to take a different path if that error occurs.
In that case you model the error handling explicitly in the process model but you make it look like a normal result and not like an error. From a business perspective it is not an error but a result, so the decision should not be made lightly. A rule of thumb is that results can be handled this way, exceptional errors should not. However, the BPMN perspective does not always have to match the technical implementation.
Example:
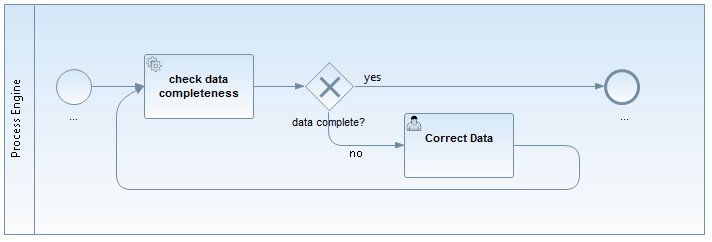
We trigger a "check data completeness" task. The Java Service might throw a "DataIncompleteException". However, if we check for completeness, incomplete data is not an exception, but an expected result, so we prefer to use an XOR-Gateway in the process flow which evaluates a process variable, e.g., "#{dataComplete==false}".
BPMN 2.0 Error Event
The BPMN 2.0 error event gives you the possibility to explicitly model errors, tackling the use case of business errors. The most prominent example is the "intermediate catching error event", which can be attached to the boundary of an activity. Defining a boundary error event makes most sense on an embedded subprocess, a call activity or a Service Task. An error will cause the alternative process flow to be triggered:
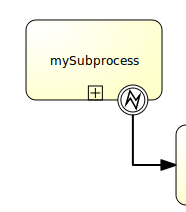
See the Error Events section of the BPMN 2.0 Implementation Reference and the Throwing Errors from Delegation Code section of the User Guide for more information.
BPMN 2.0 Compensation and Business Transactions
BPMN 2.0 transactions and compensations allow you to model business transaction boundaries (however, not in a technical ACID manner) and make sure already executed actions are compensated during a rollback. Compensation means to make the effect of the action invisible, e.g. book in goods if you have previously booked out the goods. See the BPMN Compensation event and the BPMN Transaction Subprocess sections of the BPMN 2.0 Implementation Reference for details.
Monitoring and Recovery Strategies
In case the error occurred, different recovery strategies can be applied.
Let the user retry
As mentioned above, the simplest error handling strategy is to throw the exception to the client, meaning that the user has to retry the action himself. How he does that is up to the user, normally reloading the page or clicking again.
Retry failed Jobs
If you use Jobs (async), you can leverage Cockpit as monitoring tool to handle failed jobs, in this case no end user sees the exception. Then you normally see failures in cockpit when the retries are depleted (see the Failed Jobs section of the User Guide for more information).
See the Failed Jobs in Cockpit section of the User Guide for more details.
If you don't want to use Cockpit, you can also find the failed jobs via the API yourself:
List<Job> failedJobs = processEngine.getManagementService().createJobQuery().withException().list();
for (Job failedJob : failedJobs) {
processEngine.getManagementService().setJobRetries(failedJob.getId(), 1);
}Explicit Modeling
Of course you can always explicitly model a retry mechanism as pointed out in Where is the retry in BPMN 2.0:
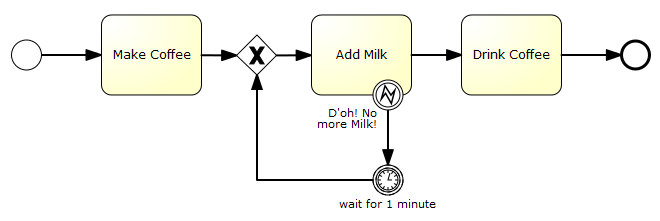
We would recommend to limit it to cases where you want to see it in the process diagram for a good reason. We prefer asynchronous continuation, as it doesn't bloat your process diagram and basically can do the same thing with even less runtime overhead, as "walking" through the modeled loop involves additional action, e.g., writing an audit log.
User Tasks for Operations
We often see something like this in projects:
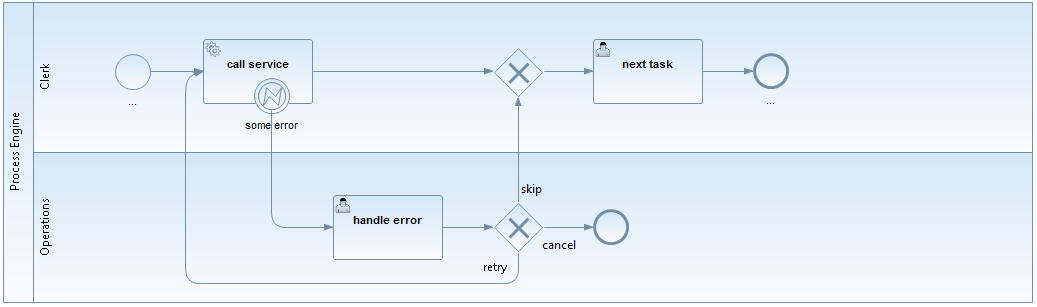
Actually this is a valid approach in which you assign errors to an operator as User Tasks and model what options he has to solve the problem. However, this is a strange mixture: We want to handle a technical error we but add it to our business process model. Where do we stop? Do we have to model it on every Service Task now?
Having a failed jobs list instead of using the "normal" task list feels like a more natural approach for this situation, which is why we normally recommend the other possibility and do not consider this to be best practice.
Process Engine
Custom Queries
Why custom queries?
The process engine offers a pretty straightforward and easy to use Java Query API. If you want to build a task list you just write something like this:
@Inject
private TaskService taskService;
public List<Task> getAllTasks() {
return taskService.createTaskQuery().taskAssignee("bernd").list();
}Easy as it is, there are basically two catches:
- You can only build queries that the API supports.
- You cannot add constraints on your domain objects.
Let us give you a simple use case example, which we implemented in the custom-queries example:
- You have a process variable "customer" holding the customerId
- You have your own entity "Customer" with all the details
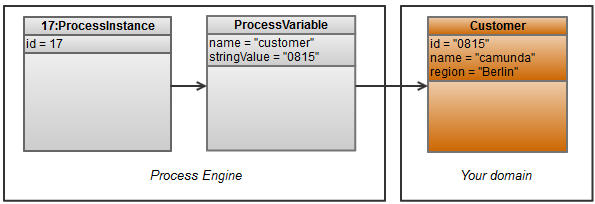
So far, a pretty common situation (please note that the object diagram has been simplified to show the relevant aspects and doesn't precisely correspond to the implementation classes). What would be easy now is to query all process instances for a customer:
@Inject
private TaskService taskService;
public List<Task> getTasks() {
return taskService.createTaskQuery().processVariableValueEquals("customer", "0815").list();
}But imagine you want to query
- All tasks for a certain region (which is part of your domain, not the process engine database)
- All tasks for customer 0815 or 4711 (the query API always assumes AND and does not support OR)
How to do this?
The "naive" implementation
Something we see very often is what we call the "naive" implementation, the easiest way you can think of: use the existing query capabilities and add an own filter to your Java code. This is easy to write for any Java developer. However, it normally queries too much information from the Process Engine's database and therefore might cause serious performance issues - so please check the alternatives below first.
For the two example queries above we could write the following code:
public List<Task> getTasks(String region) {
ArrayList<Task> resultingList = new ArrayList<Task>();
// customer Id = 0815
List<Task> list = taskService.createTaskQuery().processVariableValueEquals("customer", "0815").list();
for (Task task : list) {
String customerId = (String) runtimeService.getVariable(task.getExecutionId(), "customer");
Customer customer = customerService.getCustomer(customerId);
if (region.equals(customer.getRegion())) {
resultingList.add(task);
}
}
// OR customer Id = 4711
list = taskService.createTaskQuery().processVariableValueEquals("customer", "4711").list();
for (Task task : list) {
String customerId = (String) runtimeService.getVariable(task.getExecutionId(), "customer");
Customer customer = customerService.getCustomer(customerId);
if (region.equals(customer.getRegion())) {
resultingList.add(task);
}
}
return resultingList;
}Think about what this does:
- Query all tasks
- Create an own query for the process variable "customer" for each task
- Create another query for the customer entity for each task
- Throw away almost all of the information because we only need a couple of tasks (the region is a rather restrictive condition)
So, the code above might work in small environments, but can cause serious performance issues.
Given this, what are the alternatives? To show you other approaches used to solve this, we want to take a quick look at some persistence internals first.
Background: Persistence in the process engine
The process engine uses MyBatis for persistence: "The MyBatis data mapper framework makes it easier to use a relational database with object-oriented applications. MyBatis couples objects with stored procedures or SQL statements using a XML descriptor. Simplicity is the biggest advantage of the MyBatis data mapper over object relational mapping tools.".
In a nutshell, we parse an XML mapping file with all the SQL statements we need and set up a so called SessionFactory to talk to MyBatis (which then talks to the database via JDBC). The used mapping file can be found in the sources of the camunda BPM platform: mappings.xml. Basically, it "just" includes the other mapping files.
When creating a query via the Query API it is executed as Command object, which then delegates to MyBatis with the right query and the correct parameters. Not much magic involved here.
Possible Solution Approaches
In order to solve the requirements stated in the introduction, we can think of a couple of possible approaches:
- The naive implementation, as already explained: not recommended.
- Write custom SQL code to do your own queries: possible, but you have to mess around with SQL yourself: not recommended.
- Leverage MyBatis for your custom queries: That is actually a really powerful approach and our recommendation: see the example below.
- Use JPA: We experimented with JPA mappings for the core engine entities to allow JPA queries. If these mappings exist and you can use them in your own application combined with your own JPA stuff, then it is a possible approach. However, you have to maintain the JPA mappings yourself which involves a lot of work and we have already experienced problems with it in the past, so, basically: not recommended.
- Add redundant information, an easy, but often sufficient, approach to improve queries, which doesn't need a lot of understanding of the persistence implementation:
- Add process variables for all query parameters. In our example that would mean to add the region as its own process variable. This approach is recommended.
- Add process information to the domain mode. In our example this could mean to add a seperate entity task which is synchronized with the process engine task management. This is possible but requires some work which must be done carefully to make sure that the process engine and your domain objects are always in sync.
- Add a materialized view that joins the required database tables into one flat table.
Custom MyBatis Queries
Precondition: In order to use your own MyBatis (or all types of SQL) queries, your domain data and the process engine data must be stored in the same database. Otherwise you cannot technically construct a single SQL query, which is our goal in terms of performance optimization. If you have separate databases, discuss if you really need them (which is the case less often than you think). If the answer is 'yes' or you even work with entities only over remote service interfaces, you have to "fall back" to the redundant information approach. Maybe you can use your own entities for that redundant information.
Warning: Writing your own MyBatis queries means that you rely on the internal entity / database structure of the process engine. This is considered quite stable (as otherwise we would have to provide extensive migration scripts), but there is no guarantee. Therefore, please check your MyBatis queries on any version migration you do. This can be skipped if you have good test coverage from automated unit tests.
The following solution is implemented in the custom-queries example, where you will find a complete working example. The code snippets in this article are taken from that example.
In order to add your own MyBatis queries, you have to provide a MyBatis XML configuration file. This file can not only contain SQL commands but also mappings from relational data to Java Objects. The question is how to make MyBatis use our own configuration file, when MyBatis is already set up during the process engine startup? The easiest solution is described here. This approach leverages the existing infrastructure to access MyBatis, including connection and transaction handling, but starts up a completely separate MyBatis Session within the Process Application. This has two big advantages (and no real disadvantage):
- No extensions necessary in the engine configuration (this improves maintainability)
- The MyBatis Session is handled completely within the Process Application, which means that, e.g., classloading works out-of-the-box. This also ensures that the configuration doesn't intervene with any other Process Application.
In order to this, we start up a very special Process Engine which only does the MyBatis handling, we can ensure this by overwriting the init method. We also overwrite a hook which gets the name of the MyBatis configuration file:
public class MyBatisExtendedSessionFactory extends StandaloneProcessEngineConfiguration {
private String resourceName;
protected void init() {
throw new IllegalArgumentException("Normal 'init' on process engine only used for extended MyBatis mappings is not allowed.");
}
public void initFromProcessEngineConfiguration(ProcessEngineConfigurationImpl processEngineConfiguration, String resourceName) {
this.resourceName = resourceName;
setDataSource(processEngineConfiguration.getDataSource());
initDataSource();
initVariableTypes();
initCommandContextFactory();
initTransactionFactory();
initTransactionContextFactory();
initCommandExecutors();
initSqlSessionFactory();
initIncidentHandlers();
initIdentityProviderSessionFactory();
initSessionFactories();
}
/**
* In order to always open a new command context set the property
* "alwaysOpenNew" to true inside the CommandContextInterceptor.
*
* If you execute the custom queries inside the process engine
* (for example in a service task), you have to do this.
*/
@Override
protected Collection<? extends CommandInterceptor> getDefaultCommandInterceptorsTxRequired() {
List<CommandInterceptor> defaultCommandInterceptorsTxRequired = new ArrayList<CommandInterceptor>();
defaultCommandInterceptorsTxRequired.add(new LogInterceptor());
defaultCommandInterceptorsTxRequired.add(new CommandContextInterceptor(commandContextFactory, this, true));
return defaultCommandInterceptorsTxRequired;
}
@Override
protected InputStream getMyBatisXmlConfigurationSteam() {
return ReflectUtil.getResourceAsStream(resourceName);
}
}This allows us to access our own queries (we will show this in a moment) from our MyBatis session by constructing an Command object:
Command<List<TaskDTO>> command = new Command<List<TaskDTO>>() {
public List<TaskDTO> execute(CommandContext commandContext) {
// select the first 100 elements for this query
return (List<TaskDTO>) commandContext.getDbSqlSession().selectList("selectTasksForRegion", "Berlin", 0, 100);
}
};
MyBatisExtendedSessionFactory myBatisExtendedSessionFactory = new MyBatisExtendedSessionFactory();
myBatisExtendedSessionFactory.initFromProcessEngineConfiguration(processEngineConfiguration, "/ourOwnMappingFile.xml");
myBatisExtendedSessionFactory.getCommandExecutorTxRequired().execute(command);This is already everything you need, see a fully working solution in MyBatisExtendedSessionFactory.java, MyBatisQueryCommandExecutor.java and the example usage in TasklistService.java.
Now let's get back to the example from the beginning. We want to query all tasks of customers for a certain region. First of all, we have to write an SQL query for this. Let's assume that we have the following entity stored in the same Data-Source as the process engine:
@Entity
@Table(name="CUSTOMER")
public class Customer {
@Id
@Column(name="ID_")
private long id;
@Column(name="REGION_")
private String region;
...Now the SQL query has to join the CUSTOMER with the VARIABLES table from the process engine. Here we do an additional trick as once used for another standard problem: We join in ALL process variables to receive them together with the Tasks in one query. Maybe this is not your use case, but it might show you how powerful this approach can be. The full MyBatis Mapping can be found in customTaskMappings.xml.
<select id="selectTasksForRegion" resultMap="customTaskResultMap" parameterType="org.camunda.bpm.engine.impl.db.ListQueryParameterObject">
${limitBefore}
select distinct
T.ID_ as tID_,
T.NAME_ as tNAME_,
T.DESCRIPTION_ as tDESCRIPTION_,
T.DUE_DATE_ as tDUE_DATE_,
...
CUST.ID_ as CUSTOMER_ID_,
CUST.NAME_ as CUSTOMER_NAME_,
CUST.REGION_ as CUSTOMER_REGION_,
VAR.ID_ as VID_,
VAR.TYPE_ as VTYPE_,
VAR.NAME_ as VNAME_
...
from ${prefix}ACT_RU_TASK T
left outer join (select * from ${prefix}ACT_RU_VARIABLE where NAME_= 'customerId' ) VAR_CUSTOMER on VAR_CUSTOMER.EXECUTION_ID_ = T.EXECUTION_ID_
left outer join CUSTOMER CUST on CUST.ID_ = VAR_CUSTOMER.LONG_
right outer join ${prefix}ACT_RU_VARIABLE VAR on VAR.EXECUTION_ID_ = T.EXECUTION_ID_
<where>
<if test="parameter != null">
CUST.REGION_ = #{parameter}
</if>
</where>
${limitAfter}
</select>We will explain the joins briefly: The first two joins check if there is a process variable named "customerId" and join it to the CUSTOMER table, which allows it to add CUSTOMER columns in the select as well as in the where clause, and the last right outer join joins in all existing process variables. There is one catch in that last statement: We now get one row per process variable. Let's assume we have 10 tasks with 10 variables each, then our result set has 100 rows. This is no problem for MyBatis, it can map this to a Collection as we will see in a moment, but in this case the LIMIT statement we use for paging is applied to the overall result set. So, if we tell MyBatis to get the first 50 tasks, we only get 5 tasks, because we have 50 rows for this. This is not a general problem of the approach described here but a glitch in the SQL query provided, maybe you can think of smarter way to write this?
This brings us to the last piece of code we want to draw your attention to: The Mapping. In order to get the customer data together with the Task information we defined a seperate DTO object (DTO stands for Data Transfer Object, it basically means a Java object used as value container). This DTO holds a list of the process variables as well:
public class TaskDTO {
private String id;
private String nameWithoutCascade;
private String descriptionWithoutCascade;
private Date dueDateWithoutCascade;
private Customer customer;
private List<ProcessVariableDTO> variables = new ArrayList<ProcessVariableDTO>();
...Filling these objects with the result set from our Query is now an easy task for MyBatis with this mapping:
<resultMap id="customTaskResultMap" type="org.camunda.demo.custom.query.TaskDTO">
<id property="id" column="tID_" />
<result property="nameWithoutCascade" column="tNAME_" />
<result property="descriptionWithoutCascade" column="tDESCRIPTION_" />
<result property="dueDateWithoutCascade" column="tDUE_DATE_" />
<association property="customer" javaType="com.camunda.fox.quickstart.tasklist.performance.Customer">
<id property="id" column="CUSTOMER_ID_"/>
<result property="name" column="CUSTOMER_NAME_"/>
<result property="region" column="CUSTOMER_REGION_" />
</association>
<collection ofType="org.camunda.demo.custom.query.ProcessVariableDTO" property="variables" column="tPROC_INST_ID_" resultMap="customVariableResultMap"/>
</resultMap>
<resultMap id="customVariableResultMap" type="org.camunda.demo.custom.query.ProcessVariableDTO">
<id property="id" column="VID_" />
<result property="name" column="VNAME_" />
<result property="value" column="VTEXT_" />
</resultMap>We hope that this is somehow self-explanatory, otherwise best take a look at the MyBatis XML configuration reference.
This is all you have to do. Please check out the full code in the example, you can to run it directly on the JBoss distribution. You can easily play around with it to check if it serves your needs or to compare query performance to an implementation you had until now, maybe something similar to the naive implementation we mentioned at the beginning (and be assured: we see that really often out there ;-)).
Performance Experiences
It was really important to us to write this article because sometimes we hear that the process engine performs badly and almost every time this is related to wrongly designed queries. One customer had his project status turned to "dark yellow" (which is close to red) because of these performance issues. This solution improved performance by a factor greater than 10 and fixed paging and sorting issues, bringing the project back on track. So we think everybody should know about it!
Multi-Tenancy
Sometimes it is desired to share one Camunda installation between multiple independent parties, also referred to as tenants. While sharing an installation means sharing computational resources, the tenants' data should be separated from each other. This tutorial shows how to work with the one process engine per tenant approach.
In detail it explains how to:
- configure one process engine per tenant on a JBoss Application Server such that data is isolated by database schemas
- develop a process application with tenant-specific deployments
- access the correct process engine from a REST resource based on a tenant identifier
See the user guide for a general introduction on multi-tenancy and the different options Camunda offers.
Before Starting
Before starting, make sure to download the Camunda BPM JBoss distribution and extract it to a folder. We will call this folder $CAMUNDA_HOME in the following explanations.
Configuring the Database
Before configuring process engines, we have to set up a database schema for every tenant. In this section we will explain how to do so.
Start up JBoss by running $CAMUNDA_HOME/start-camunda.{bat/sh}. After startup, open your browser and go to http://localhost:8080/h2/h2. Enter the following configuration before connecting:
- Driver Class: org.h2.Driver
- JDBC URL: jdbc:h2:./camunda-h2-dbs/process-engine
- User Name: sa
- Password: sa
Create two different schemas for the different process engines:
create schema TENANT1;
create schema TENANT2;Next, inside each schema, create the database tables. To achieve this, get the SQL create scripts
from the jboss distribution from the sql/create/ folder inside your distribution.
Inside the h2 console, execute the create scripts (h2_engine_7.2.0.sql and
h2_identity_7.2.0.sql) scripts after selecting the appropriate schema for the current connection:
set schema TENANT1;
<<paste sql/create/h2_engine_7.2.0.sql here>>
<<paste sql/create/h2_identity.2.0.sql here>>
set schema TENANT2;
<<paste sql/create/h2_engine_7.2.0.sql here>>
<<paste sql/create/h2_identity.2.0.sql here>>The following screenshot illustrates how to create the tables inside the correct schema:
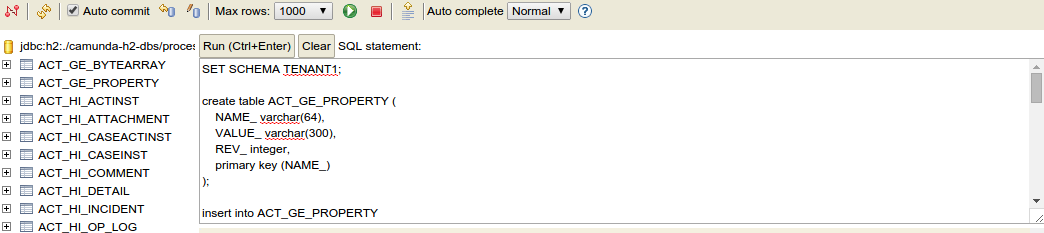
Next, hit run.
After creating the tables in the two schemas, the UI should show the following table structure:
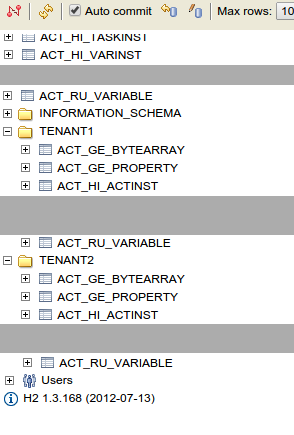
Now, stop JBoss.
Configuring Process Engines
In this step, we configure a process engine for each tenant. We ensure that these engines access the database schemas we have previously created. This way, process data of a tenant cannot interfere with that of another.
Open the file $CAMUNDA_HOME/server/jboss-as-{version}/standalone/configuration/standalone.xml. In that file, navigate to the configuration of the camunda jboss subsystem, declared in an XML element <subsystem xmlns="urn:org.camunda.bpm.jboss:1.1">. In this file, add two entries to the <process-engines> section (do not remove default engine configuration):
The configuration of the process engine for tenant 1:
<process-engine name="tenant1">
<datasource>java:jboss/datasources/ProcessEngine</datasource>
<history-level>none</history-level>
<properties>
<property name="databaseTablePrefix">TENANT1.</property>
<property name="jobExecutorAcquisitionName">default</property>
<property name="isAutoSchemaUpdate">false</property>
<property name="authorizationEnabled">true</property>
<property name="jobExecutorDeploymentAware">true</property>
</properties>
<plugins>
<!-- plugin enabling Process Application event listener support -->
<plugin>
<class>org.camunda.bpm.application.impl.event.ProcessApplicationEventListenerPlugin</class>
</plugin>
</plugins>
</process-engine>The configuration of the process engine for tenant 2:
<process-engine name="tenant2">
<datasource>java:jboss/datasources/ProcessEngine</datasource>
<history-level>none</history-level>
<properties>
<property name="databaseTablePrefix">TENANT2.</property>
<property name="jobExecutorAcquisitionName">default</property>
<property name="isAutoSchemaUpdate">false</property>
<property name="authorizationEnabled">true</property>
<property name="jobExecutorDeploymentAware">true</property>
</properties>
<plugins>
<!-- plugin enabling Process Application event listener support -->
<plugin>
<class>org.camunda.bpm.application.impl.event.ProcessApplicationEventListenerPlugin</class>
</plugin>
</plugins>
</process-engine>(find the complete standalone.xml here)
By having a look at the datasource configuration, you will notice that the data source is shared between all engines. The property databaseTablePrefix points the engines to different database schemas. This makes it possible to shares resources like a database connection pool between both engines. Also have a look at the entry jobExecutorAcquisitionName. The job acquisition is part of the job executor, a component responsible for executing asynchronous tasks in the process engine (cf. the job-executor element in the subsystem configuration). Again, the jobExecutorAcquisitionName configuration enables reuse of one acquisition thread for all engines.
The approach of configuring multiple engines also allows you to differ engine configurations apart from the database-related parameters. For example, you can activate process engine plugins for some tenants while excluding them for others.
Develop a Tenant-Aware Process Application
In this step, we describe a process application that deploys different processes for the two tenants. It also exposes a REST resource that returns a tenant's process definitions. To identify the tenant, we provide a user name in the REST request. In the implementation, we use CDI to transparently interact with the correct process engine based on the tenant identifier.
The following descriptions highlight the concepts related to implementing multi-tenancy but are not a step-by-step explanation to develop along. Instead, make sure to checkout the code on github. The code can be built and deployed to JBoss right away and contains all the snippets explained in the following sections.
Set Up the Process Application
In the project, we have set up a plain Camunda EJB process application.
In pom.xml, the camunda-engine-cdi and camunda-ejb-client dependencies are added:
<dependency>
<groupId>org.camunda.bpm</groupId>
<artifactId>camunda-engine-cdi</artifactId>
</dependency>
<dependency>
<groupId>org.camunda.bpm.javaee</groupId>
<artifactId>camunda-ejb-client</artifactId>
</dependency>These are required to inject process engines via CDI.
Configure a Tenant-specific Deployment
In the folder src/main/resources, we have added a folder processes and two subfolders tenant1 and tenant2. These folders contain a process for tenant 1 and a process for tenant 2, respectively.
In order to deploy the two definitions to the two different engines, we have added a file src/main/resources/META-INF/processes.xml with the following content:
<process-application
xmlns="http://www.camunda.org/schema/1.0/ProcessApplication"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<process-archive name="tenant1-archive">
<process-engine>tenant1</process-engine>
<properties>
<property name="resourceRootPath">classpath:processes/tenant1/</property>
<property name="isDeleteUponUndeploy">false</property>
<property name="isScanForProcessDefinitions">true</property>
</properties>
</process-archive>
<process-archive name="tenant2-archive">
<process-engine>tenant2</process-engine>
<properties>
<property name="resourceRootPath">classpath:processes/tenant2/</property>
<property name="isDeleteUponUndeploy">false</property>
<property name="isScanForProcessDefinitions">true</property>
</properties>
</process-archive>
</process-application>This file declares two process archives. By the process-engine element, we can specify the engine to which an archive should be deployed. By the resourceRootPath, we can assign different portions of the contained process definitions to different process archives.
Build a Simple JAX-RS Resource
To showcase the programming model for multi-tenancy with CDI, we have added a simple REST resource that returns all deployed process definitions for a process engine. The resource has the following source code:
@Path("/process-definition")
public class ProcessDefinitionResource {
@Inject
protected ProcessEngine processEngine;
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<ProcessDefinitionDto> getProcessDefinitions() {
List<ProcessDefinition> processDefinitions =
processEngine.getRepositoryService().createProcessDefinitionQuery().list();
return ProcessDefinitionDto.fromProcessDefinitions(processDefinitions);
}
}Note that the distinction between tenants is not made in this resource.
Make CDI Injection Tenant-aware
We want the injected process engine to always be the one that matches the current tenant making a REST request. For this matter, we have added a request-scoped tenant bean:
@RequestScoped
public class Tenant {
protected String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}To populate this bean with the tenant ID for the current user, we add a RestEasy interceptor. This interceptor is called before a REST request is dispatched to the ProcessDefinitionResource. It has the following content:
@Provider
@ServerInterceptor
public class TenantInterceptor implements PreProcessInterceptor {
protected static final Map<String, String> USER_TENANT_MAPPING = new HashMap<String, String>();
static {
USER_TENANT_MAPPING.put("kermit", "tenant1");
USER_TENANT_MAPPING.put("gonzo", "tenant2");
}
@Inject
protected Tenant tenant;
public ServerResponse preProcess(HttpRequest request, ResourceMethod method) throws Failure, WebApplicationException {
List<String> user = request.getUri().getQueryParameters().get("user");
if (user.size() != 1) {
throw new WebApplicationException(Status.BAD_REQUEST);
}
String tenantForUser = USER_TENANT_MAPPING.get(user.get(0));
tenant.setId(tenantForUser);
return null;
}
}Note that the tenant ID is determined based on a simple static map. Of course, in real-world applications one would implement a more sophisticated lookup procedure here.
To resolve the process engine based on the tenant, we have specialized the process engine producer bean as follows:
@Specializes
public class TenantAwareProcessEngineServicesProducer extends ProcessEngineServicesProducer {
@Inject
private Tenant tenant;
@Override
@Named
@Produces
@RequestScoped
public ProcessEngine processEngine() {
String processEngineName = tenant.getId();
if (processEngineName != null) {
ProcessEngine processEngine = BpmPlatform.getProcessEngineService().getProcessEngine(processEngineName);
if (processEngine != null) {
return processEngine;
} else {
throw new ProcessEngineException("No process engine found for tenant id '" + processEngineName + "'.");
}
} else {
throw new ProcessEngineException("No tenant id specified. A process engine can only be retrieved based on a tenant.");
}
}
@Override
@Produces
@Named
@RequestScoped
public RuntimeService runtimeService() {
return processEngine().getRuntimeService();
}
...
}The producer determines the engine based on the current tenant. It encapsulates the logic of resolving the process engine for the current tenant entirely. Every bean can simply declare @Inject ProcessEngine without specifying which specific engine is addressed to work with the current tenant's engine.
Deploy the Application to JBoss
Start up JBoss. Build the process application and deploy the resulting war file to JBoss.
Make a GET request (e.g., by entering the URL in your browser) against the following URL to get all process definitions deployed to tenant 1's engine: http://localhost:8080/multi-tenancy-tutorial/process-definition?user=kermit
Only the process for tenant 1 is returned.
Make a GET request against the following URL to get all process definitions deployed to tenant 2's engine: http://localhost:8080/multi-tenancy-tutorial/process-definition?user=gonzo
Only the process for tenant 2 is returned.
Go to Camunda Cockpit and switch the engine to tenant1 on the following URL (you will be asked to create an admin user first):
http://localhost:8080/camunda/app/cockpit/tenant1
Only the process for tenant 1 shows up. You can check the same for tenant 2 by switching to engine tenant2.
And you're done! :)
User Interface
JSF Task Forms
Adding JSF Forms to your process application
If you add JSF forms as described below, you can easily use them as external task forms.
A working example can be found in the examples repository.
The BPMN process used for this example is shown in the image below:
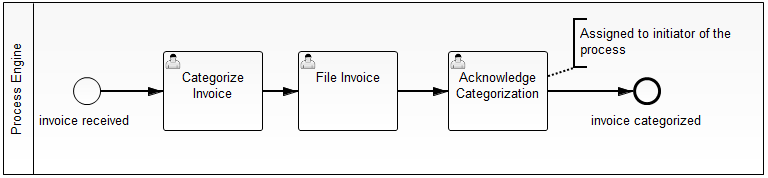
In this process model we added so called form keys to
- the Start Event "invoice received". This is the form the user has to complete to start a new process instance.
- the User Tasks. These are the forms the user has to complete when completing user tasks that are assigned to him.
This is how the forms are referenced in the BPMN 2.0 XML with the camunda:formKey attribute:
<startEvent id="start" name="invoice received"
camunda:formKey="app:sample-start-form.jsf"/>
<userTask id="categorize-invoice" name="Categorize Invoice"
camunda:formKey="app:sample-task-form-1.jsf" />
<userTask id="file-invoice" name="File Invoice"
camunda:formKey="app:sample-task-form-2.jsf" />
<userTask id="acknowledge-categorization" name="Acknowledge Categorization"
camunda:formKey="app:acknowledge-form.jsf" />Creating Simple User Task Forms
Create a JSF page in src/main/webapp/WEB-INF representing a form used for User Tasks. A very simple task form is shown below:
<!DOCTYPE HTML>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core">
<f:view>
<h:head>
<f:metadata>
<f:event type="preRenderView" listener="#{camundaTaskForm.startTaskForm()}" />
</f:metadata>
<title>Task Form: #{task.name}</title>
</h:head>
<h:body>
<h1>#{task.name}</h1>
<h:form id="someForm">
<p>
Here you would see the actual form to work on the task in a design
normally either matching your task list or your business application
(or both in the best case).
</p>
<h:commandButton id="complete" value="Task Completed"
action="#{camundaTaskForm.completeTask()}" />
</h:form>
</h:body>
</f:view>
</html>Note that you need camunda-engine-cdi in order to have the camundaTaskForm bean available.
How does this work?
If the user clicks on "Start to work on task" ( ) in the tasklist, he will follow a link to this form, including the taskId and the callback URL (the URL to access the central tasklist) as GET-Parameters. Accessing this form will trigger the special CDI bean
) in the tasklist, he will follow a link to this form, including the taskId and the callback URL (the URL to access the central tasklist) as GET-Parameters. Accessing this form will trigger the special CDI bean camundaTaskForm which
- starts a conversation,
- remembers the callback URL
- starts the User Task in the process engine, meaning the bean sets the start date and assigns the task to the CDI business process scope (see CDI Integration for details).
For that, you just need to add this code block to the beginning of your JSF view:
<f:metadata>
<f:event type="preRenderView" listener="#{camundaTaskForm.startTaskForm()}" />
</f:metadata>Submit the form by calling the camundaTaskForm bean again, which:
- Completes the task in the process engine, causing the current token to advance in the process
- Ends the conversation
- Triggers a redirect to the callback URL of the tasklist
<h:commandButton id="complete" value="task completed" action="#{camundaTaskForm.completeTask()}" />Note that the command button doesn't have to be on the same form, you might have a whole wizard containing multiple forms in a row before having the completeTask button. This will work because of the conversation running in the background.
Access process variables
In the forms you can access your own CDI beans as usual and also access the camunda CDI beans. This makes it easy to access process variables, e.g., via the processVariables CDI bean:
<h:form id="someForm">
<p>Here you would see the actual form to work on the task in some design normally either matching you task list or your business application (or both in the best case).</p>
<table>
<tr>
<td>
Process variable <strong>x</strong> (given in in the start form):
</td>
<td>
<h:outputText value="#{processVariables['x']}" />
</td>
</tr>
<tr>
<td>
Process variable <strong>y</strong> (added in this task form):
</td>
<td>
<h:inputText value="#{processVariables['y']}" />
</td>
</tr>
<tr>
<td></td>
<td>
<h:commandButton id="complete" value="Task Completed"
action="#{camundaTaskForm.completeTask()}" />
</td>
</tr>
</table>
</h:form>This is rendered to a simple form:
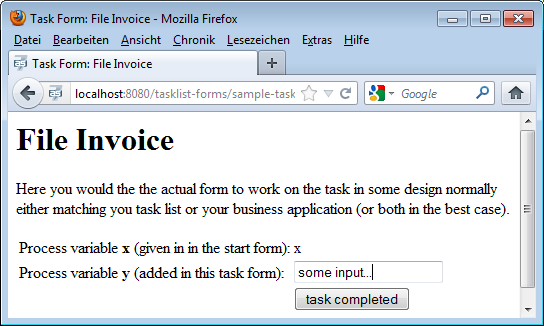
The same mechanism can be used to start a new process instance:
<!DOCTYPE HTML>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core">
<f:view>
<f:metadata>
<f:event type="preRenderView" listener="#{camundaTaskForm.startProcessInstanceByKeyForm()}" />
</f:metadata>
<h:head>
<title>Start Process: #{camundaTaskForm.processDefinition.name}</title>
</h:head>
<h:body>
<h1>#{camundaTaskForm.processDefinition.name}</h1>
<p>Start a new process instance in version: #{camundaTaskForm.processDefinition.version}</p>
<h:form id="someForm">
<p>
Here you see the actual form to start a new process instance, normally
this would be in some design either matching you task list or your business
application (or both in the best case).
</p>
<table>
<tr>
<td>
Process variable <strong>x</strong>:
</td>
<td>
<h:inputText value="#{processVariables['x']}" />
</td>
</tr>
<tr>
<td></td>
<td>
<h:commandButton id="start" value="Start Process Instance"
action="#{camundaTaskForm.completeProcessInstanceForm()}" />
</td>
</tr>
</table>
</h:form>
</h:body>
</f:view>
</html>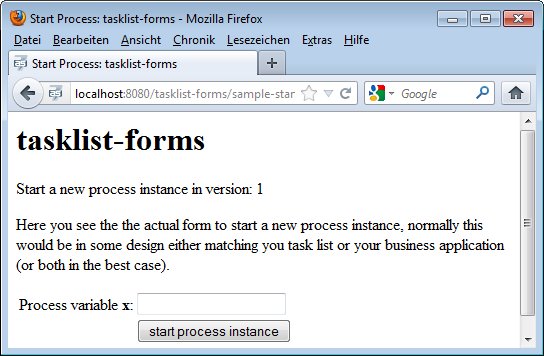
If the user clicks on "Start a process instance" ( ) in the tasklist and chooses the process your start form is assigned to, he will follow a link to this form, including the processDefinitionKey and the callback URL (the URL to access the central tasklist) as GET-Parameters. Accessing this form will trigger the special CDI bean
) in the tasklist and chooses the process your start form is assigned to, he will follow a link to this form, including the processDefinitionKey and the callback URL (the URL to access the central tasklist) as GET-Parameters. Accessing this form will trigger the special CDI bean camundaTaskForm which:
- Starts a conversation
- Remembers the callback URL to the centralized tasklist
You need to add this code block to the beginning of your JSF view:
<f:metadata>
<f:event type="preRenderView" listener="#{camundaTaskForm.startProcessInstanceByIdForm()}" />
</f:metadata>Submitting the start form now:
- Starts the process instance in the process engine
- Ends the conversation
- Triggers a redirect to the callback URL of the tasklist
<h:commandButton id="start" value="Start Process Instance" action="#{camundaTaskForm.completeProcessInstanceForm()}" />Note that the command button doesn't have to be on the same form, you might have a whole wizard containing multiple forms in a row before having the completeProcessInstanceForm button. This will work because of the conversation running in the background.
Styling your task forms
We use Twitter Bootstrap in our tasklist - so best add this to your Process Application as well and you can easily polish your UI:
To include CSS and Javascript libraries in your project you can add them to your maven project as dependencies.
<dependencies>
<!-- ... -->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>To use them, add tags like the following ones to your JSF page. If you have several forms, it may be helpful to create a template that you can refer to from your forms to avoid redundancies..
<h:head>
<title>your title</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<!-- CSS Stylesheets -->
<h:outputStylesheet library="webjars/bootstrap/3.1.1/css" name="bootstrap.css"/>
<h:outputStylesheet library="css" name="style.css"/>
<!-- Javascript Libraries -->
<h:outputScript type="text/javascript" library="webjars/bootstrap/3.1.1/js" name="bootstrap.js" />
</h:head>Calling Services
Communication among Processes using Web Services
Let's assume that you have two processes running on different Process Engines on different servers. This could for example be a system with a central process engine that orchestrates several application-specific process engines:
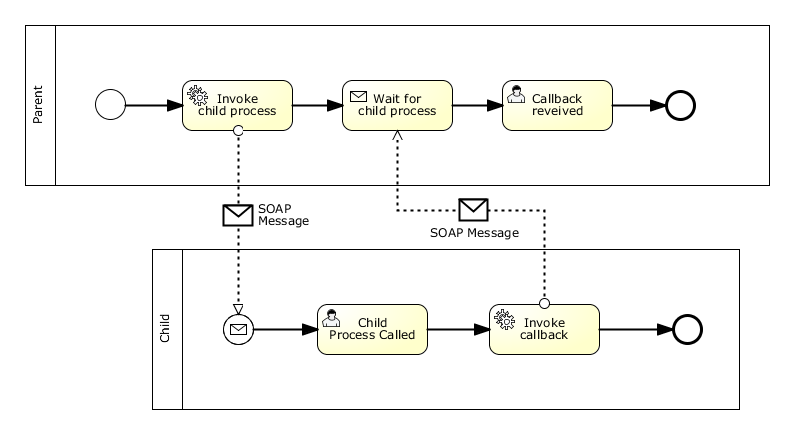
The collaboration above contains two processes: The parent and the child.
The communication is done conceptually via messages, technologically by SOAP Messages via Web Services. This means that:
- The parent process uses a Service Task to invoke a Web Service that starts the child process
- The parent waits for completion of the child by using a Receive Task
- At the end of the child process, a Service Task performs the callback to the parent by calling another Web Service provided by the parent. The callback URL can be a parameter of the communication
- A unique id is generated for this communication and sent to and returned by the child as a correlation key that identifies the process instance that is to be called back
There is one related example available which demonstrates two process engines communicating via web services: https://github.com/camunda/camunda-consulting/tree/master/snippets/inter-process-communication-ws. It implements the whole communication within one Maven project including a proper automated test case.
Web Services for Invocation and Callback
This scenario requires two Web Services to be provided – one on each side:
- Invocation Service: The first service is provided on the server where the child is deployed and will be called by the parent to start the child.
- Callback Service: The second service is provided on the server where the parent process is deployed and will be called by the child to signal its completion to the parent.
A common way to implement Web Services in Java is to use JAX-WS annotations on a POJO and use a Web Service framework like Apache Axis or Apache CXF as a provider for the underlying protocols and tools. The examples below use Apache CXF, which is available out of the box in JBoss AS 7.
Process Invocation Web Service
The Process Invocation Service has four parameters: The process to be started, a URL to call back when the process completed, a correlation id to identify the process instance to call back and a String payload. The latter three are stored as process variables into the new process instance. The payload could of course use more complex types. We just use String here for simplicity of the example.
@WebService(name = "ProcessInvocationService")
public class ProcessInvocation {
public static final String CALLBACK_URL = "callbackURL";
public static final String CALLBACK_CORRELATION_ID = "callbackCorrelationId";
public static final String PAYLOAD = "payload";
@Inject
private RuntimeService runtimeService;
public void invokeProcess(String processDefinitionKey, String callbackUrl, String correlationId, String payload) {
Map<String, Object> variables = new HashMap<String, Object>();
variables.put(CALLBACK_URL, callbackUrl);
variables.put(CALLBACK_CORRELATION_ID, correlationId);
variables.put(PAYLOAD, payload);
runtimeService.startProcessInstanceByKey(processDefinitionKey, variables);
}
}Process Callback Web Service
The Process Callback Service takes three arguments: The process that has completed, the correlation id that has been assigned during the invocation of that process, and a payload, which is again just a String for simplicity. With the first two arguments the process instance waiting for that callback is located and resumed while storing the payload as a process variable.
@WebService(name = "ProcessCallbackService")
public class ProcessCallback {
public static final String PAYLOAD_RECEIVED_FROM_CALLBACK = "payloadReceivedFromCallback";
@Inject
private RuntimeService runtimeService;
public void invokeProcessCallback(String calledProcess, String correlationId, String payload) {
Execution execution = runtimeService
.createExecutionQuery()
.variableValueEquals(ProcessInvocationClient.CORRELATION_ID_PREFIX + calledProcess, correlationId)
.singleResult();
Map<String, Object> variables = new HashMap<String, Object>();
variables.put(PAYLOAD_RECEIVED_FROM_CALLBACK, payload);
runtimeService.signal(execution.getId(), variables);
}
}Generation of WSDL and Web Service Clients
When a Java class with a @WebService annocation is deployed, the application server automatically generates a WSDL description and provides the according Web Service, on a default JBoss AS 7 installation you will find the two WSDL's here:
- http://localhost:8080/inter-process-communication-ws/ProcessInvocation?wsdl
- http://localhost:8080/inter-process-communication-ws/ProcessCallback?wsdl
A Maven plugin provided by CXF can then be used to generate a Java client out of the WSDL, just add this to your pom.xml:
...
<build>
<plugins>
<plugin>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-codegen-plugin</artifactId>
<version>2.5.2</version>
<executions>
<execution>
<id>generate-sources</id>
<phase>generate-sources</phase>
<configuration>
<sourceRoot>${project.build.directory}/generated/cxf</sourceRoot>
<wsdlOptions>
<wsdlOption>
<wsdl>${basedir}/src/main/resources/ProcessInvocationService.wsdl</wsdl>
</wsdlOption>
<wsdlOption>
<wsdl>${basedir}/src/main/resources/ProcessCallbackService.wsdl</wsdl>
</wsdlOption>
</wsdlOptions>
</configuration>
<goals>
<goal>wsdl2java</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
...Integration of Web Services into Processes
The Web Services clients generated by CXF are wrapped into CDI beans that are called by the processes using expressions.
<serviceTask id="ServiceTask_1" activiti:expression="#{processInvocationClient.invokeProcess('inter-process-communication-ws-child', execution)}" name="Invoke child process" />@Named
public class ProcessInvocationClient {
public static final String CORRELATION_ID_PREFIX = "correlationIdForInvocationOf_";
public static final String SAMPLE_PAYLOAD_PREFIX = "sample-payload-";
@Inject
ServiceRegistry serviceRegistry;
public void invokeProcess(String processDefinitionKey, DelegateExecution execution) {
// lookup service URL
URL wsdlLocation = serviceRegistry.getWsdlLocation(processDefinitionKey);
// prepare CXF client
ProcessInvocationService service = new ProcessInvocationService_Service(wsdlLocation)
.getProcessInvocationServicePort();
// generate callback URL and correlation ID
String callbackUrl = serviceRegistry.getWsdlLocation("inter-process-communication-ws-parent").toString();
String correlationId = UUID.randomUUID().toString();
// store correlation ID
execution.setVariable(CORRELATION_ID_PREFIX + processDefinitionKey, correlationId);
// call service
service.invokeProcess(processDefinitionKey, callbackUrl , correlationId, SAMPLE_PAYLOAD_PREFIX + correlationId);
}
}You can see that we used a simple "ServiceRegistry" to query the right WSDL. This is basically a simple Java map, but could be exchanged by any existing Registry. In a customer project we for example used WSO2 for this purpose.
<serviceTask id="ServiceTask_1" activiti:expression="#{processCallbackClient.invokeProcessCallback(payload, execution)};" name="Invoke callback">@Named
public class ProcessCallbackClient {
public void invokeProcessCallback(String payload, DelegateExecution execution) throws MalformedURLException {
// lookup service URL
URL wsdlLocation = new URL((String) execution.getVariable(ProcessInvocation.CALLBACK_URL));
// prepare CXF client
ProcessCallbackService service = new ProcessCallbackService_Service(wsdlLocation)
.getProcessCallbackServicePort();
// restore correlation information
String calledProcess = "inter-process-communication-ws-child";
String correlationId = (String) execution.getVariable(ProcessInvocation.CALLBACK_CORRELATION_ID);
// call service
service.invokeProcessCallback(calledProcess, correlationId, payload);
}
}Cockpit
How to develop a Cockpit plugin
In this how-to we will walk through the steps needed to develop a Cockpit plug-in. While doing so, we will develop a simple plug-in that displays the number of process instances per deployed process definition on the dashboard page of Cockpit:
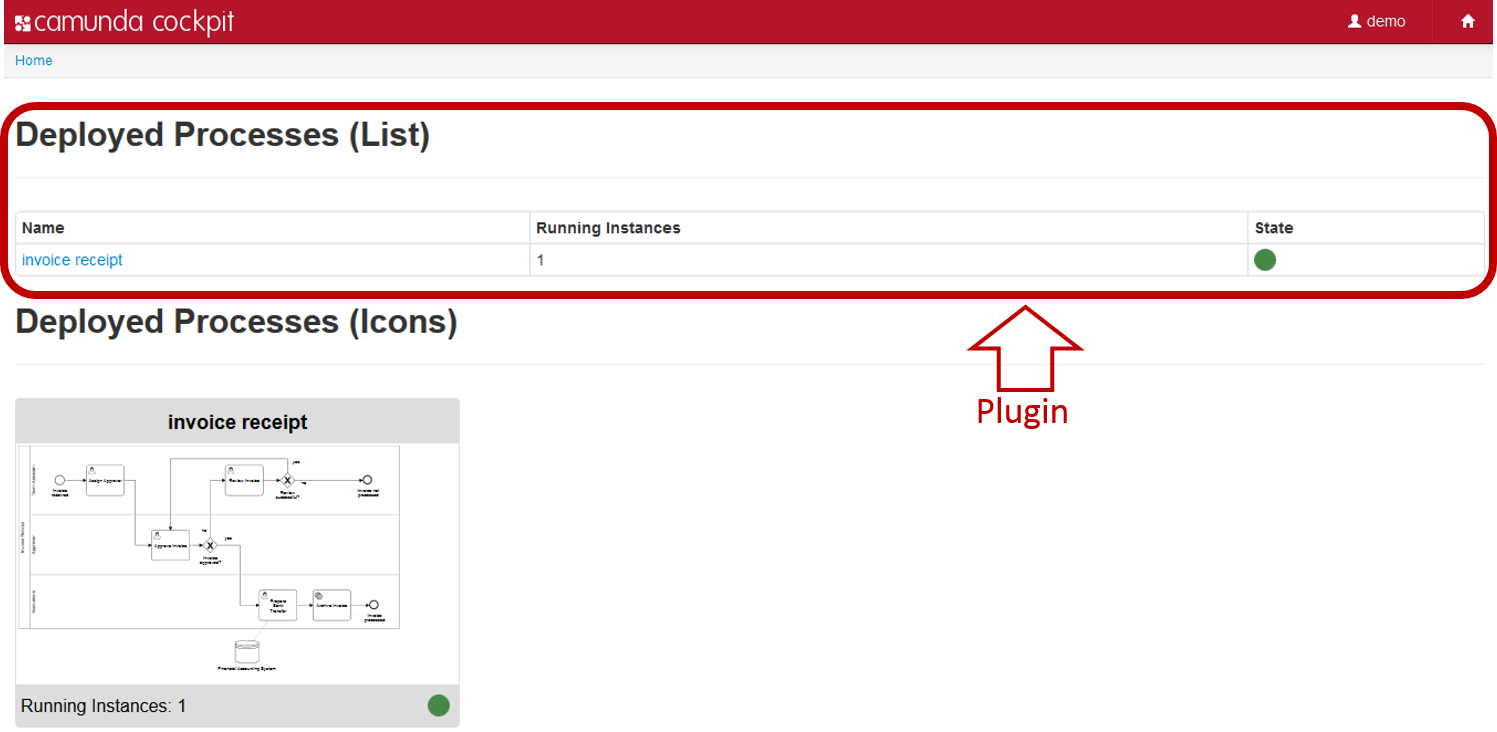
Please take a look at the Cockpit Plug-ins section of the User Guide for the basics first.
Server side
We will walk through the important aspects of developing the server-side parts of the plug-in, i.e., creating a plug-in jar, defining a custom query and exposing that query via a JAX-RS resource.
Plug-in archive
As a first step we create a maven jar project that represents our plug-in library. Inside the projects pom.xml we must declare a dependency to the camunda webapp core with the maven coordinates org.camunda.bpm.webapp:camunda-webapp-core. The project contains all the infrastructure necessary to create and test the server-side parts of a plug-in.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.camunda.bpm.cockpit.plugin</groupId>
<artifactId>cockpit-sample-plugin</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>cockpit-sample-plugin</name>
<dependencies>
<dependency>
<groupId>org.camunda.bpm.webapp</groupId>
<artifactId>camunda-webapp-core</artifactId>
<version>7.2.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>Plug-in main class
The main entry point for a plug-in is the service provider interface (SPI) org.camunda.bpm.cockpit.plugin.spi.CockpitPlugin. Each plug-in must provide an implementation of this class and register it via META-INF/services.
We will go ahead and create an implementation of that API called SampleCockpitPlugin.
package org.camunda.bpm.cockpit.plugin.sample;
import org.camunda.bpm.cockpit.plugin.spi.impl.AbstractCockpitPlugin;
public class SamplePlugin extends AbstractCockpitPlugin {
public static final String ID = "sample-plugin";
public String getId() {
return ID;
}
}By inheriting from org.camunda.bpm.cockpit.plugin.spi.impl.AbstractCockpitPlugin, we ensure that the plug-in is initialized with reasonable defaults.
To register the plug-in with Cockpit, we must put its class name into a file called org.camunda.bpm.cockpit.plugin.spi.CockpitPlugin that resides in the directory META-INF/services. That will publish the plug-in via the Java ServiceLoader facilities.
Testing Plug-in Discovery
Now let's go ahead and write a test case that makes sure the plug-in gets discovered properly. Before we do so, we need to add test dependencies to our project pom.xml.
<dependencies>
...
<!-- test dependencies -->
<dependency>
<groupId>org.camunda.bpm</groupId>
<artifactId>camunda-engine</artifactId>
<version>7.2.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.3.171</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
...The next step consists of wiring the camunda webapp and the process engine. To do this, we need to create a Service Provider that implements the interface ProcessEngineProvider and declare it in a file called org.camunda.bpm.engine.rest.spi.ProcessEngineProvider that resides in the directory src/test/resources/META-INF/services/. The file should contain the following content:
org.camunda.bpm.cockpit.plugin.test.application.TestProcessEngineProviderThe TestProcessEngineProvider is provided with the camunda webapp core, uses the methods of the class org.camunda.bpm.BpmPlatform and exposes the default process engine.
The class org.camunda.bpm.cockpit.plugin.test.AbstractCockpitPluginTest can work as a basis for Cockpit plugin tests. It initializes the Cockpit environment around each test and bootstraps a single process engine that is made available to Cockpit and the plug-in.
A first test may look as follows:
package org.camunda.bpm.cockpit.plugin.sample;
import org.camunda.bpm.cockpit.Cockpit;
import org.camunda.bpm.cockpit.plugin.spi.CockpitPlugin;
import org.camunda.bpm.cockpit.plugin.test.AbstractCockpitPluginTest;
import org.junit.Assert;
import org.junit.Test;
public class SamplePluginsTest extends AbstractCockpitPluginTest {
@Test
public void testPluginDiscovery() {
CockpitPlugin samplePlugin = Cockpit.getRuntimeDelegate().getPluginRegistry().getPlugin("sample-plugin");
Assert.assertNotNull(samplePlugin);
}
}In the test #testPluginDiscovery we use the internal Cockpit API to check if the plug-in was recognized.
Before we can actually run the test, we need to create a camunda.cfg.xml to be present on the class path (usually under src/test/resources). That file configures the process engine to be bootstrapped.
Let's ahead and create the file with the following content:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="processEngineConfiguration" class="org.camunda.bpm.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<property name="jdbcUrl" value="jdbc:h2:mem:camunda;DB_CLOSE_DELAY=1000" />
<property name="jdbcDriver" value="org.h2.Driver" />
<property name="jdbcUsername" value="sa" />
<property name="jdbcPassword" value="" />
<!-- Database configurations -->
<property name="databaseSchemaUpdate" value="true" />
<!-- job executor configurations -->
<property name="jobExecutorActivate" value="false" />
<property name="history" value="full" />
</bean>
</beans>Custom query
The plug-in mechanism allows us to provide additional SQL queries that may be run against the process engine database. Those queries must be defined via MyBatis mapping files.
To implement a custom query, we will create a file sample.xml in the directory org/camunda/bpm/cockpit/plugin/sample/queries with the following content:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cockpit.sample">
<resultMap id="processInstanceCountMap" type="org.camunda.bpm.cockpit.plugin.sample.db.ProcessInstanceCountDto">
<result property="key" column="KEY_" jdbcType="VARCHAR" />
<result property="instanceCount" column="INSTANCES_" jdbcType="INTEGER" />
</resultMap>
<select id="selectProcessInstanceCountsByProcessDefinition" resultMap="processInstanceCountMap">
select d.KEY_, count(d.KEY_) INSTANCES_
from ACT_RU_EXECUTION e JOIN ACT_RE_PROCDEF d ON e.PROC_DEF_ID_ = d.ID_
group by d.KEY_
</select>
</mapper>Note both the usage of a custom namespace (cockpit.sample) as well as the result mapping to the plug-in provided class org.camunda.bpm.cockpit.plugin.sample.db.ProcessInstanceCountDto.
We need to define the class to which the result is mapped:
package org.camunda.bpm.cockpit.plugin.sample.db;
public class ProcessInstanceCountDto {
private String key;
private int instanceCount;
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public int getInstanceCount() {
return instanceCount;
}
public void setInstanceCount(int instanceCount) {
this.instanceCount = instanceCount;
}
}Additionally, we need to publish the mapping file by overriding the method #getMappingFiles() in our plug-in class:
public class SamplePlugin extends AbstractCockpitPlugin {
// ...
@Override
public List<String> getMappingFiles() {
return Arrays.asList("org/camunda/bpm/cockpit/plugin/sample/queries/sample.xml");
}
}Testing Queries
To test that the plug-in defined query actually works, we extend our testcase. By using the Cockpit provided service QueryService we can verify that the query can be executed:
public class SamplePluginsTest extends AbstractCockpitPluginTest {
// ...
@Test
public void testSampleQueryWorks() {
QueryService queryService = getQueryService();
List<ProcessInstanceCountDto> instanceCounts =
queryService
.executeQuery(
"cockpit.sample.selectProcessInstanceCountsByProcessDefinition",
new QueryParameters<ProcessInstanceCountDto>());
Assert.assertEquals(0, instanceCounts.size());
}
}Note that #getQueryService() is merely a shortcut to the service that may also be accessed via Cockpit's main entry point, the org.camunda.bpm.cockpit.Cockpit class.
Defining and publishing plug-in services
Plug-ins publish their services via APIs defined through JAX-RS resources.
First, we need to add the JAX-RS API to our projects pom.xml. That is best done by including the following dependency:
<dependencies>
...
<!-- provides jax-rs (among other APIs) -->
<dependency>
<groupId>org.jboss.spec</groupId>
<artifactId>jboss-javaee-6.0</artifactId>
<type>pom</type>
<scope>provided</scope>
<version>3.0.2.Final</version>
</dependency>
...A server-side plug-in API consists of a root resource and a number of sub resources that are provided by the root resource. A root resource may inherit from org.camunda.bpm.cockpit.plugin.resource.AbstractPluginRootResource to receive some basic traits. It must publish itself on the path plugin/$pluginName via a @Path annotation.
A root resource for our plug-in may look as follows:
package org.camunda.bpm.cockpit.plugin.sample.resources;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import org.camunda.bpm.cockpit.plugin.resource.AbstractPluginRootResource;
import org.camunda.bpm.cockpit.plugin.sample.SamplePlugin;
@Path("plugin/" + SamplePlugin.ID)
public class SamplePluginRootResource extends AbstractPluginRootResource {
public SamplePluginRootResource() {
super(SamplePlugin.ID);
}
@Path("{engineName}/process-instance")
public ProcessInstanceResource getProcessInstanceResource(@PathParam("engineName") String engineName) {
return subResource(new ProcessInstanceResource(engineName), engineName);
}
}Note that a sub resource gets initialized by the plug-in when requests to {engineName}/process-instance are being made. That ensures that a Cockpit service is multi-tenancy ready out of the box (i.e. capable to work with all process engines provided by the camunda BPM platform).
A sub-resource may extend org.camunda.bpm.cockpit.plugin.resource.AbstractPluginResource to get initialized with the correct process engine mappings. The resource shown below exposes our custom SQL query to the client when accessing the resource via GET.
package org.camunda.bpm.cockpit.plugin.sample.resources;
import java.util.List;
import javax.ws.rs.GET;
import org.camunda.bpm.cockpit.db.QueryParameters;
import org.camunda.bpm.cockpit.plugin.resource.AbstractPluginResource;
import org.camunda.bpm.cockpit.plugin.sample.db.ProcessInstanceCountDto;
public class ProcessInstanceResource extends AbstractPluginResource {
public ProcessInstanceResource(String engineName) {
super(engineName);
}
@GET
public List<ProcessInstanceCountDto> getProcessInstanceCounts() {
return getQueryService()
.executeQuery(
"cockpit.sample.selectProcessInstanceCountsByProcessDefinition",
new QueryParameters<ProcessInstanceCountDto>());
}
}To include plug-in resources into the Cockpit application those resources must be published in the main plug-in file by overriding #getResourceClasses():
import org.camunda.bpm.cockpit.plugin.sample.SamplePlugin;
public class SamplePlugin extends AbstractCockpitPlugin {
// ...
@Override
public Set<Class<?>> getResourceClasses() {
Set<Class<?>> classes = new HashSet<Class<?>>();
classes.add(SamplePluginRootResource.class);
return classes;
}
// ...
}Given the above setup the resource class extends the Cockpit API with the following paths
GET $cockpit_api_root/plugin/sample/$engine/process-instanceTesting JAX-RS Resources
To test your JAX-RS resources you can instantiate them directly during a plug-in test case. Alternatively, you can write a real API test using arquillian. See PluginApiTest for an example.
Now we are done with the server-side parts of the plug-in. Next, we will go ahead and write the client-side extension that exposes the functionality to the user.
Client side
The client-side part of a Cockpit plug-in consists of an extension to the Cockpit webapp client application. It is served through the plug-in serverside extension as a static plug-in asset.
Static plugin assets
When using AbstractPluginRootResource as the plug-in resources base class, serving static assets is already built in. The root resource accepts a GET request under /static to serve plug-in-provided client-side resources. Per convention, these resources must reside in a /plugin-webapp/$plugin_id directory absolute to the classpath root.
So, let's create a file plugin-webapp/$plugin_id/info.txt in the src/main/resources directory of our project. We can give it the following content (optional):
FOO BARTesting Assets
To test that the assets are served, we can either implement a test case or test the matter manually after we integrated the plug-in into the Cockpit webapp.
Integration into Cockpit
There are two ways to add your plugin to the camunda BPM webapp.
- You can copy it to the
WEB-INF/libfolder of the camunda webapp. - You can set up a maven war overlay for the camunda webapp.
The first solution is the simplest: if you dowloaded the tomcat distribution, you can copy the plugin
jar file to the /server/apache-tomcat-${tomcat-version}/webapps/camunda/WEB-INF/lib/ folder and
restart the server.
plugin.js main file
Each plug-in must contain a file app/plugin.js in the plug-ins assets directory (i.e., plugin-webapp/$plugin_id). That file bootstraps the client-side plug-in and registers it with Cockpit. To do so it must declare and return an angular module named cockpit.plugin.$plugin_id using requireJS.
Without going too deeply into detail, our plugins plugin.js may look like this:
define(['angular'], function(angular) {
var DashboardController = ["$scope", "$http", "Uri", function($scope, $http, Uri) {
$http.get(Uri.appUri("plugin://sample-plugin/:engine/process-instance"))
.success(function(data) {
$scope.processInstanceCounts = data;
});
}];
var Configuration = ['ViewsProvider', function(ViewsProvider) {
ViewsProvider.registerDefaultView('cockpit.dashboard', {
id: 'process-definitions',
label: 'Deployed Processes',
url: 'plugin://sample-plugin/static/app/dashboard.html',
controller: DashboardController,
// make sure we have a higher priority than the default plugin
priority: 12
});
}];
var ngModule = angular.module('cockpit.plugin.sample-plugin', []);
ngModule.config(Configuration);
return ngModule;
});The file defines the angular module cockpit.plugin.sample-plugin and registers a plug-in with the Cockpit plug-in service (ViewsProvider#registerDefaultView()).
HTML view
To complete the example, we need to define the HTML file app/dashboard.html as a plug-in asset:
<div>
<h1>Process Instances per Definition</h1>
<table class="table table-bordered table-hover table-condensed">
<thead>
<tr>
<th>Key</th>
<th>Instances</th>
</tr>
</thead>
<tbody>
<tr data-ng-repeat="count in processInstanceCounts">
<td>{{ count.key }}</td>
<td>{{ count.instanceCount }}</td>
</tr>
</tbody>
</table>
</div>This file provides the actual view to the user.
When deploying the extended camunda webapplication on the camunda BPM platform, we can see the plug-in in action.
Summary
You made it! In this how-to we walked through all important steps required to build a Cockpit plug-in, from creating a plug-in skeleton through defining server-side plug-in parts up to implementing the client-side portions of the plug-in.
Additional resources
Appendix
How client-side plugins work
Some experience in JavaScript development as well as knowledge about AngularJS and RequireJS is beneficial to understanding this subsection.
The client-side plug-in infrastructure provides extensions to the Cockpit core application through views that expose data provided by a plugins server-side API. We'll quickly elaborate on how the interaction between a plug-in and the camunda webapplication happens.
A plug-in is defined in an app/plugin.js file that gets served as static plug-in asset:
define([
'jquery',
'angular',
'http://some-url/some-library.js',
'./someOtherModule.js'
], function($, angular) {
var ViewController = ['$scope', function($scope, Uri) {
// perform logic
// uris to plugin assets and apis may be resolved via Uri#appUri
// by prefixing those apis with 'plugin://'
var pluginServiceUrl = Uri.appUri('plugin://myPlugin/default/process-definition');
}];
var ngModule = angular.module('cockpit.plugin.myPlugin', ['some.other.angularModule']);
// publish the plugin to cockpit
ngModule.config(function(ViewsProvider) {
ViewsProvider.registerDefaultView('cockpit.some-view', {
id: 'some-view-special-plugin',
label: 'Very Special Plugin',
url: 'plugin://myPlugin/static/app/view.html',
controller: ViewController
});
});
return ngModule;
});As the file is loaded as a RequireJS module, dependencies (in terms of other RequireJS modules) may be specified.
The plug-in must register itself with the ViewsProvider via a module configuration hook.
From within Cockpit, views are included using the view directive:
<view provider="viewProvider" vars="viewProviderVars" />The actual provider that defines the view as well as the published variables are defined by the responsible controller in the surrounding scope:
function SomeCockpitController($scope, Views) {
$scope.viewProvider = Views.getProvider({ component: 'cockpit.some-view'});
// variable 'foo' will be available in the view provider scope
$scope.viewProviderVars = { read: [ 'foo' ]};
}Modeler
Creating Custom Tasks for camunda Modeler
By providing custom tasks to the camunda Modeler, vendors may provide special tasks to users through the Modelers palette. Along with these custom tasks, vendors may ship extensions to the properties panel through which task-specific properties can be maintained.

This tutorial guides you through the creation of a custom task extension for the camunda Modeler.
The source of custom task extension that is developed in this tutorial is available as a sample application.
Before You Start
In this tutorial, we take a deeper look at Eclipse extension points and plug-in development. Please refer to the Extending the Eclipse IDE - Plug-in development and Eclipse Extension Points and Extensions tutorials on the matter if you would like to learn more.
Make sure you have the development environment for the camunda Modeler set up. This typically involves setting up the Eclipse instance with the necessary dependencies, checking out the Modeler sources and importing the project(s) into a workspace.
Creating a Plug-in Project
To extend the Modeler, you need to create an Eclipse plug-in project. Do so via New > Project > Plug-in Project.

The next steps ask you for the location of the project

as well vendor and versioning information.

You may optionally choose to generate an activator for your project to hook into the plug-ins life cycle.
Building a Custom Task Plug-in
The Modeler gives you the ability to contribute custom task types via the
org.camunda.bpm.modeler.plugin.customtask extension point. Via this extension point you must provide information about the custom task through the ICustomTaskProvider interface.
Configure project dependencies
Add the following entry to your META-INF/MANIFEST.MF file to enable commonly used dependencies:
Require-Bundle: org.eclipse.emf,
org.eclipse.core.runtime,
org.eclipse.ui,
org.eclipse.ui.ide,
org.eclipse.ui.workbench,
org.eclipse.ui.views.properties.tabbed,
org.camunda.bpm.modeler;bundle-version="2.3.0",
org.eclipse.bpmn2,
org.eclipse.graphiti,
org.eclipse.graphiti.uiHook into the extension point
Create or edit the plugin.xml in your project root with the following contents:
<?xml version="1.0" encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension point="org.camunda.bpm.modeler.plugin.customtask">
<provider class="com.mycompany.modeler.tasks.MyCustomTaskProvider">
</provider>
</extension>
</plugin>This tells Eclipse you are going to implement the custom task extension point using the class com.mycompany.modeler.tasks.MyCustomTaskProvider.
You are ready to write your custom task provider. Go ahead and create the class with the following contents:
public class MyCustomTaskProvider extends AbstractCustomTaskProvider {
@Override
public String getId() {
return "mycompany.myCustomTask";
}
@Override
public String getTaskName() {
return PluginConstants.getMyCustomTaskName();
}
@Override
public boolean appliesTo(EObject eObject) {
return PluginConstants.isMyCustomTask(eObject);
}
}Additionally, create the utility class com.mycompany.modeler.tasks.PluginConstants as shown below
public class PluginConstants {
public static final EStructuralFeature CLASS_STRUCTURAL_FEATURE = ModelPackage.eINSTANCE.getDocumentRoot_Class();
public static final String CLASS_VALUE = "com.mycompany.services.MyService";
public static boolean isMyCustomTask(EObject eObject) {
return eObject instanceof ServiceTask && CLASS_VALUE.equals(eObject.eGet(CLASS_STRUCTURAL_FEATURE));
}
public static String getMyCustomTaskName() {
return "My Custom Task";
}
}Resolve missing dependencies via Add XXX to imported packages. In case dependencies are unresolvable, you may have problems in your build path. Check the project requirements to work around the issue.
What did we do? The class MyCustomTaskProvider provides the basic implementation of the custom task. It exposes the following method:
#getId(): provides a unique id of the custom task#getName(): provides the task name#appliesTo(EObject): tells the modeler whether a givenEObjectrepresents a custom task
The utility PluginConstants provides reusable utilities such as the implementation of the custom task check as well as the task name.
Activation of the extension
The behavior shipped with a custom task provider will automatically activate whenever ICustomTaskProvider#appliesTo(EObject) returns as true. This means that our implementation MyCustomTaskProvider activates for all objects of type ServiceTask that have a class property set to com.mycompany.services.MyService (cf. PluginConstants#isMyCustomTask(EObject)).
In other words: It is all plain old BPMN 2.0 with camunda extensions and any service task with an XML definition like
<serviceTask camunda:class="com.mycompany.services.MyService" />will be recognized as a custom task once opened with the camunda Modeler and our installed plug-in.
Adding a Property Tab
To show a special property section for a custom task, we must implement the method ICustomTaskProvider#getTabSection(). The method must return an instance of ISection that gets added to the property tabs for a task.
Add the following lines to our MyCustomTaskProvider class:
@Override
public ISection getTabSection() {
return new MyCustomTaskTabSection();
}We implement the tab section via the class MyCustomTaskTabSection.
public class MyCustomTaskTabSection extends AbstractTabSection {
@Override
protected Composite createCompositeForObject(Composite parent, EObject businessObject) {
return new MyCustomTaskTabSectionFactory(this, parent).createCompositeForBusinessObject((BaseElement) businessObject);
}
private static class MyCustomTaskTabSectionFactory extends AbstractTabCompositeFactory<BaseElement> {
public MyCustomTaskTabSectionFactory(GFPropertySection section, Composite parent) {
super(section, parent);
}
@Override
public Composite createCompositeForBusinessObject(BaseElement baseElement) {
Text endpointText = FieldInjectionUtil.createLongStringText(
section, parent, "Endpoint", "endpoint", baseElement);
PropertyUtil.attachNoteWithLink(section, endpointText,
"For more information search <a href=\"http://google.com\">google</a>");
return parent;
}
}
}The MyCustomTaskTabSection delegates creating the tab contents to an instance of AbstractTabCompositeFactory. It creates the contents of the tab in #createCompositeForBusinessObject(EObject). Our implementation adds a text area with the label Endpoint that maps to a field injection of type text with the name endpoint. Additionally, it renders the note For more information search google right below the text.
We may now start Eclipse with the extension installed via Run > Run As > Eclipse Application.
After we assigned the class com.mycompany.services.MyService to a service task and refreshed the properties panel (i.e. deselect and select the task again) we should see our property tabs extension in action.

When editing the input field labeled Endpoint and saving the file, the BPMN 2.0 diagram file should reflect the changes.
Helpers available in property tabs
There are two helpers that aid you in the creation of property sections:
FieldInjectionUtiloffers static helpers that create input elements that map to<camunda:field />injection declarations.PropertyUtiloffers static helpers for creating various kinds of input elements, including help texts.
To learn more about what else is possible in property panels, browse the subclasses of AbstractTabCompositeFactory.
Palette Integration
The way a custom task is integrated into the new element palette may be configured via ICustomTaskProvider#getPaletteIntegration().
To enable palette integration for our service task, add the following lines to the MyCustomTaskProvider class
@Override
public IPaletteIntegration getPaletteIntegration() {
return PaletteIntegration.intoCompartmentNamed("My Company");
}This specifies that a create handle for our custom task should be shown in a category My Company in the palette. Alternatively, we may choose to integrate the task into already existing categories by returning PaletteIntegration.intoCompartmentForCategory(Category.TASKS).
Now we must tell the Modeler how to create the custom task.
This is done by exposing a custom set of modeling features, including a create feature via an IFeatureContainer.
Defining Custom Task Features
Feature containers, implementing the interface IFeatureContainer, tell the Modeler how certain modeling operations are implemented on diagram elements.
These operations include:
- Creating an element
- Moving, resizing or removing an element
- Decorating an element
Custom task providers may ship their own feature containers by publishing them via ICustomTaskProvider#getFeatureContainer().
You must configure a feature container in your custom task provider as soon as you want to be able to create a custom task via the palette or want to change its graphical representation.
Expose a feature container
Create the class MyCustomTaskFeatureContainer with the following definition
public class MyCustomTaskFeatureContainer extends ServiceTaskFeatureContainer {
@Override
public boolean canApplyTo(Object o) {
return o instanceof EObject && PluginConstants.isMyCustomTask((EObject) o);
}The feature container inherits the behavior provided to service tasks (extends ServiceTaskFeatureContainer) and only applies to instances of the custom service (cf. MyCustomTaskFeatureContainer#canApplyTo(Object).
Now expose it through the custom task provider by adding the following lines to the MyCustomTaskProvider class:
@Override
public IFeatureContainer getFeatureContainer() {
return new MyCustomTaskFeatureContainer();
}If you enabled the palette integration, you should now see the custom service task entry in the palette as shown below

Add a custom create feature
To be detected as a custom task, a newly created element must have the class attribute set to com.mycompany.services.MyService.
We can achieve this by overriding the create feature provided by the ServiceTaskFeatureContainer with custom behavior that explicitly sets the attribute when the task is being created.
To do so, add the following lines to the MyCustomTaskFeatureContainer class:
@Override
public ICreateFeature getCreateFeature(IFeatureProvider fp) {
String taskName = PluginConstants.getMyCustomTaskName();
String createDescription = "A task that talks to an endpoint";
return new AbstractCreateTaskFeature<ServiceTask>(fp, taskName, createDescription) {
@Override
protected String getStencilImageId() {
return Images.IMG_16_SERVICE_TASK;
}
@Override
public ServiceTask createBusinessObject(ICreateContext context) {
ServiceTask serviceTask = super.createBusinessObject(context);
serviceTask.eSet(PluginConstants.CLASS_STRUCTURAL_FEATURE, PluginConstants.CLASS_VALUE);
return serviceTask;
}
@Override
public EClass getBusinessObjectClass() {
return Bpmn2Package.eINSTANCE.getServiceTask();
}
};
}Note that you can also specify the image, the task name displayed in the palette as well as a description for the create feature.
After restarting Eclipse, the palette entry should now display the name of your custom task.

Building a Customized Modeler Distribution
As a final step we need to build a customized Eclipse that contains the camunda Modeler and our custom task plug-in. One of the various ways to do this is via a product configuration that allows you to generate Eclipse applications as well as update sites.
To start, create a new product configuration named customModeler.product via New > Other... > Plug-in Configuration and specify that you would like to create a configuration using basic settings.
Configure the resulting view similar to the following screenshot

Now add the camunda Modeler as well as the custom task plug-in to the list of dependencies (Dependencies tab).

Finally resolve the required dependencies via Add Required Plug-ins.
You may now start, verify and export the product configuration using the handles at the top right.
Summary
In this how-to we created a simple custom task extension for the camunda Modeler. This involved creating a plug-in project and writing a custom task extension for the camunda Modeler. Through the extension we were able to add a property panel tab as well as a palette entry for the custom task. Finally, we saw how an Eclipse distribution can be built that ships the camunda Modeler, including the custom task extension.
Advanced topics
There are a number of further topics we did not touch yet. These include:
- Color custom tasks on the diagram
- Change the icon
- Provide additional actions via the context pad
Check out the advanced custom task example project that showcases these features.